Whither DSGE Estimation?
Things are not as bad as made out

Note: This post is more wonkish than is typical. Normal service will resume in the future. Thanks to Johannes Pfeifer for making his Dynare files publicly available for the Smets-Wouters model, which allowed me to produce all of the results in this post.
The use of dynamic stochastic general equilibrium (DSGE) models has become ubiquitous in academic macroeconomics and central banks since their inception in the 1980s. These models are dynamic, as they feature agents who make decisions over time. They are stochastic in the sense that they feature uncertainty about the processes which ultimately drive fluctuations in the model’s set of variables. Finally, they are general equilibrium models since prices, interest rates and quantities are all determined simultaneously in a matter that means all agents are satisfying their optimality conditions. After the financial crisis of 2007-09, these models were subject to a wealth of criticism. For example, see Joseph Stiglitz’s very influential paper from 2017. Some of this criticism was well-founded in my view, although a lot of it was not, and it should be noted that many of the more reasonable critiques have been incorporated into mainstream DSGE models during the decade since. However, most criticism was directed towards the fundamental principles of DSGE models, for example, criticising the validity of the representative agent assumption or highlighting that the models did not sufficiently account for the role of the financial sector and the frictions this generates for the macroeconomy as a whole.
In a provocative and interesting recent paper, Daniel J. McDonald and Cosma Rohilla Shalizi — two statisticians — direct their criticism towards a different aspect of the DSGE literature, namely the process by which these models are estimated. They make two key points which I will quote from Shalizi’s blog post on the subject:
Even if the Smets-Wouters model was completely correct about the structure of the economy, and it was given access to centuries of stationary data, it would predict very badly, and many "deep" parameters would remain very poorly estimated;
Swapping the series around randomly improves the fit a lot of the time, even when the results are substantive nonsense.
The Smets-Wouters (2007) model is a large-scale DSGE that represents a benchmark in the literature since it contains a wealth of frictions that macroeconomists typically see as relevant in practice. This was a very influential model that forms the basis for many others used by central banks and financial institutions. In their AER paper, Smets and Wouters estimate their model with US data and find that the model can outperform Bayesian VARs (a different macro technique that does not take a stand on the explicit structure of the economic world) in-sample. This had been a severe knock on DSGE models for a while and was one reason why the private sector had mostly taken a pretty dim view of them for their purposes.
McDonald and Shalizi’s (MS henceforth) critique is highly worrying on its surface. They are basically saying in the first of the two points above that if we take a DSGE model where we know the true set of parameters, use the parameterized model to generate fake, simulated data, and then estimate the model on the simulated data, the procedure will not reliably get at the true parameters. Obviously in practice when we estimate these models, we do not know the true parameters (else we wouldn’t bother), but this is a way of testing the estimation performance in a laboratory setting where we know the true data-generating process. If the model cannot find the truth when we know what the truth actually is ex-ante, we should be highly skeptical about estimates produced on real-world data. As such, this is a low bar. They find that the model is unable to clear this low bar, however, with many parameter estimates deviating substantially from their true values, and parameter estimation error failing to decline as the length of the simulated sample increases.
This result stood out to me since in my own work I have often conducted a very similar exercise, checking that a model can correctly recover parameters when estimated on simulated data before taking it to real data. It should be noted that this is standard practice when estimating DSGE models, in contrast to what MS imply1. For example, Schmitt-Grohe and Uribe (2012) check that their estimation procedure correctly recovers the true parameters by estimating their model on simulated data of the same length as their empirical sample. When I have done this in the past, the performance has typically been very good, in contrast to what MS find. I thus wanted to conduct my own version of their tests on the Smets-Wouters model. I will not exactly replicate what MS do in their paper, but will instead try to do what I believe the typical macroeconomist would do before estimating their model on real world data. I will use the Dynare package in Matlab to do everything, which is used almost universally in practice. This is a notable difference from MS:
" To estimate the model we minimize the negative log likelihood, penalized by the prior. This is the same as finding the maximum a posteriori estimate in a Bayesian setting. Because the likelihood is ill-behaved, having many flat sections as well as local minima, we used R’s optimr package. We estimated the parameter using both the simulated annealing method, which stochastically explores the likelihood surface in a principled manner, and the conjugate gradient technique. Each procedure was started at 5 random initializations (drawn from the prior distribution) and run for 50,000 iterations (likelihood evaluations) for each starting point."
This is all well and good, and there is nothing wrong with using R rather than Dynare, but the benefit of Dynare is that it is explicitly designed for solving and estimating macro models, and includes many useful diagnostic tests. For example, a common issue in practice is finding the global mode of the posterior density during estimation, and failing to do this can lead to significant problems with convergence during the Metropolis Hastings algorithm that that follows. E.g. Johannes Pfeifer shows that the original estimation of Jermann and Quadrini (2012) suffers from this exact issue, and when corrected leads to significantly different parameter estimates and various other conclusions. Dynare has many different mode finders built in, with some explicitly designed to deal with the issue of finding the global mode for a multimodal posterior density, as well as checks to verify the global mode has indeed been found. The package has been developed through a rich community of developers and users, meaning that many bugs have been found and subsequently addressed over the years. This gives me confidence that it works well for estimation, and any problems that still persist are genuine.
First, I will run some identification checks on the model, which is another useful feature that Dynare offers. Although MS describe the literature on the identification of DSGE models as “tangential” to what they are looking at, it is the central issue in reality. If a parameter is poorly identified, increasing the amount of data will have a limited effect on how accurately it is estimated. It is well-known that this weak identification is an issue with many DSGE models, and there are many papers on the topic such as Canova and Sala (2009), Iskrev (2010), Komunjer and Ng (2011), and many others. This motivates the use of Bayesian techniques to estimate macro models, where prior information on potentially poorly identified parameters is incorporated. The latter two of these aforementioned papers present diagnostic tests which allow a practitioner to assess how well the set of parameters is identified, which are implemented in Dynare. Let's have a look at how well the set of estimates parameters in the SW are identified given the set of parameter priors and observed variables used in the data:
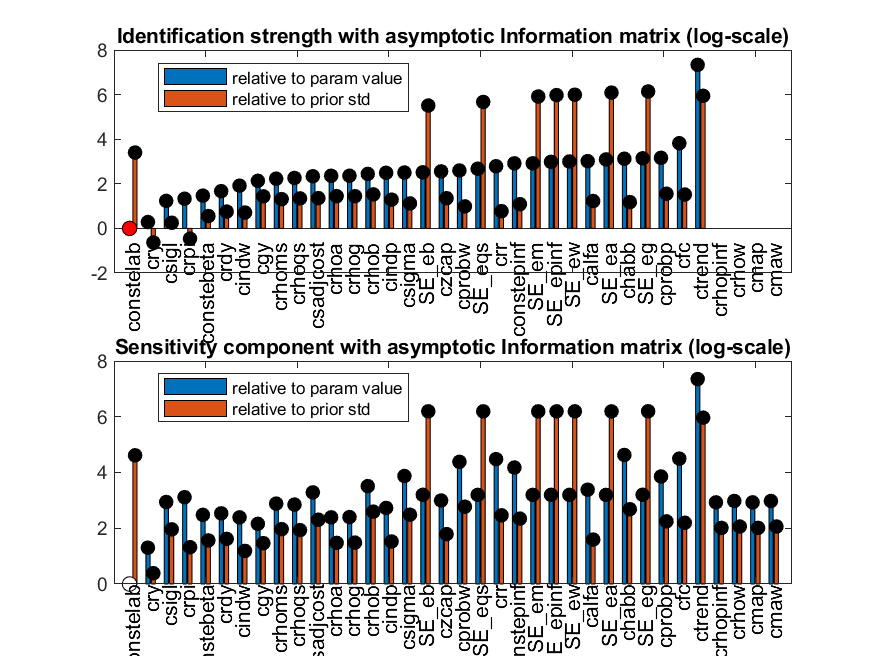
It appears as if four parameters are not identified, but as noted by Johannes Pfeifer in his Dynare file for the SW model, this is actually not the case:
" Note that at the prior mean, [cmap,crhopinf] and [cmaw,crhow] are pairwise collinear. Thus, running identification at the prior mean will return a warning. But this is only a local issue. These parameters are only indistinguishable at the prior mean, but not at different points. "
The other parameters are mostly all fairly well identified. It is definitely good practice to do this identification test since for some DSGE models there will be parameters which will be very poorly identified, or completely unidentified.
Next, I will generate simulated data from the SW model with the parameters calibrated to the posterior mode that they find in the original paper. I will then estimate the model on the simulated data, comparing each estimated parameter to its 'true' value. I use the mode_compute = 9 option in Dynare, which is a mode-finder designed to find the global mode, and then I will use 20,000 draws in the Metropolis-Hastings algorithm used to evaluate the posterior. I will do this for simulated samples of varying lengths, starting with a length (N) of 300 quarters, which roughly corresponds to the length of macroeconomic data we typically work with in practice given data availability. I will then increase this to 1000, 2000 and finally 5000 quarters, evaluating how the estimation error (the difference between the estimated parameter and the 'true' parameter) evolves. Looking first at the plot for the 300-quarter case:

The estimated model does a good job of recovering the true parameters even in this realistic sample length scenario. The points don't fall exactly on the 45-degree line of course, but the errors are not huge. This is in contrast to what MS find (quote edited to remove parameter symbols):
For instance the elasticity of labour supply with respect to the real wage, is consistently underestimated by about -93%. The data provides essentially no information about the parameter which measures the dependence of real wages on lagged inflation. Other parameters which are poorly estimated include the steady-state elasticity of the capital adjustment cost function. In all these cases, estimation is biased, so using the estimated values from the real data to draw conclusions about the real economy is unwise.
In my estimation with N=300, I find that the estimated value for the elasticity of labour supply with respect to the real wage is 1.75 relative to the true value of 1.95, the dependence of real wages on lagged inflation parameter is estimated to be 0.30 vs the true value of 0.32, and the steady-state elasticity of the capital adjustment cost function is estimated to be 0.23 rather than the true value of 0.27. These errors are clearly not large. The root mean squared error (RMSE) for the full set of parameters is 0.09, which is again not dramatic by any means.
Repeating this exercise for the full array of simulated sample lengths:

The RMSE of the parameter set declines as the sample length increases, in line with the notion of consistency of the estimator. The results here suggest the critique that the Smets-Wouters model cannot succeed, even when estimating it on simulated data generated from itself, is not justified. I cannot explain exactly why I am getting such different results, which is rather unsatisfying, but if I had to guess I would ascribe it to the Dynare vs R differences. Personally, I am inclined to trust the results generated in Dynare for the reasons previously stated. It should be noted that Joshua Brault also conducted a very similar exercise to what I have described here, and found very similar results.
The second point MS make is that relabelling variables used to estimate the model as one another can lead to a better fit. I am less sure what to make of this criticism. A point worth making is that, as is well known, many macroeconomic variables display very high levels of correlation with each other, and as a result, this could attenuate the impact of swapping variables around on parameter estimates. An additional point made eloquently by Otilia Boldea on Twitter is that these variable swaps produce a model that is deliberately misspecified and consequently you are estimating the wrong likelihood. Ultimately this means that this exercise is not informative about any particular deficiency of the model and is purely a statistical exercise.


I typically welcome critiques of the macro paradigm, including those that do not come from insiders but rather from another discipline as is the case here. My view is that this is an important mechanism by which things improve. A good example of this came during the pandemic, with epidemiological models naturally receiving a lot of scrutiny which revealed some pressing issues beneath the hood. However, this particular line of criticism made here by Macdonald and Shalizi seems to be overstated at best. It is certainly not accurate to say that the Smets-Wouters model cannot recover the true parameters even when it serves as the data-generating process, and the variable-swapping critique may not be as damning as the authors make out. To clarify for the avoidance of doubt, I am by no means saying that DSGE estimation has no issues at all. Indeed, identification is a serious issue in practice but this is something macroeconomists are well aware of and take steps to test for and address. Further, model misspecification is definitely a problem. Den Haan and Drechsel (2021) find that the Smets-Wouters model suffers from this issue and provides some correctives.
Interdisciplinary critiques are ultimately a double-edged sword. On the one hand, a fresh perspective on an entrenched status quo is undoubtedly useful and should be welcomed. On the other, one cannot expect someone unfamiliar with a field to know all of the relevant literature, and as a result, it is unsurprising that some established wisdom gets missed in the process. Unfortunately, Macdonald and Shalizi’s critique of DSGE estimation seems to feature a good deal of the latter at the expense of the former.
From Shalizi’s blog post: “But "let's try out the estimator on simulation output" is, or ought to be, an utterly standard diagnostic, and it too seems to be lacking, despite the immense controversial literature about DSGEs“.